
Exploring generic AI-assisted document aggregation and classification
Introduction
The concept of AI agents has gained significant attention. Agents are autonomous entities that can perceive their environment, make decisions, and take actions to achieve specific goals. They can be designed to perform a wide range of tasks, from simple data processing to complex problem-solving.
One area where agents can be applied is document aggregation and classification. Imagine having a system that can search for relevant resources based on an outline you provide, ask clarifying questions, and then proceed to gather, filter, summarize, analyze, and classify the information. This system would not only save time and effort but also provide a structured and organized output for further use.
LangChain has built LangGraph which enables the creation of stateful, multi-actor applications using language models. LangGraph extends the LangChain Expression Language, allowing for the coordination of multiple chains or actors across different steps of computation in a cyclic manner. It draws inspiration from systems like Pregel and Apache Beam, making it well-suited for building agent-like behaviors.

The idea
The proposed idea is to create a document/resource aggregation and classification system using LangGraph. The system would take an outline of the desired resources as input, along with any specific classification requirements. It would then engage in a dialogue with the user, asking clarifying questions to better understand their needs and preferences.
Once the system has a clear understanding of the user's requirements, it would initiate a search process. This could involve querying the internet, accessing existing knowledge bases, or a combination of both. The system would employ intelligent search algorithms to identify relevant resources based on the provided outline and classification criteria.
After gathering a pool of potential resources, the system would proceed to filter and refine the results. It would apply various techniques, such as keyword matching, semantic analysis, to determine the relevance and quality of each resource. The goal is to narrow down the search results to a curated set of high-quality, pertinent documents.
Next, the system would perform summarization and analysis on the selected resources. It would extract key information, identify main themes, and generate concise summaries for each document. This step aims to provide the user with a quick overview of the content without the need to read through entire documents.
In addition to summarization, the system would classify the resources based on the specified criteria. This could include categorizing documents by topic, format, source, or any other relevant attributes. The classification process would leverage provided or predefined taxonomies to assign appropriate labels to each resource.
Throughout the process, the system would maintain a detailed log of its actions, including the search queries, filtering criteria, summarization techniques, and classification decisions. This log would serve as a valuable reference for understanding how the system arrived at its final output.
Finally, the system would store the aggregated and classified resources in a structured format, such as a database or a file system. It would provide the user with a convenient way to access and download the curated dataset, along with the associated metadata and classifications.
Proposed LangGraph structure
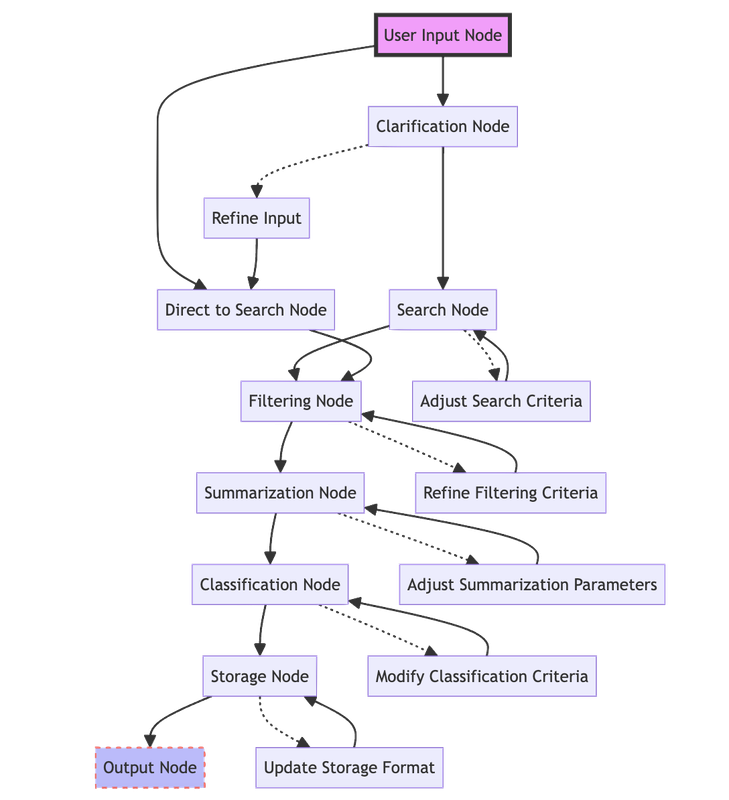
To implement this document aggregation and classification system using LangGraph, the following graph structure could be considered:
- User Input Node: Accepts the resource outline and classification requirements from the user.
- Clarification Node: Engages in a dialogue with the user to ask clarifying questions and refine the requirements.
- Search Node: Performs searches on the internet or knowledge bases based on the refined requirements.
- Filtering Node: Applies filtering techniques to refine the search results and select relevant resources.
- Summarization Node: Generates summaries and extracts key information from the selected resources.
- Classification Node: Classifies the resources based on the specified criteria using machine learning algorithms.
- Storage Node: Stores the aggregated and classified resources in a structured format.
- Output Node: Provides the user with access to the curated dataset and associated metadata.
The edges between the nodes would define the flow of data and control. For example, the User Input Node would pass the initial requirements to the Clarification Node, which would then feed the refined requirements to the Search Node. The Search Node would pass the search results to the Filtering Node, and so on.
Conclusion
The proposed document aggregation and classification system using LangGraph demonstrates the potential of agents in streamlining information retrieval and organization.
The benefits of such a system are numerous. It can save time and effort by automating tedious manual searches and curation. It can provide users with a curated dataset tailored to their specific needs, enabling them to focus on analysis and decision-making rather than data gathering. Moreover, the system's ability to maintain a detailed log of its actions ensures transparency and reproducibility.
While the proposed system is a conceptual exploration, it highlights the exciting possibilities that arise when combining the power of agents with the capabilities of LangGraph. As we continue to develop and refine these technologies, we can expect to see more sophisticated and efficient systems for document aggregation and classification, ultimately empowering users with quick access to relevant and structured information.
If you would like to explore these ideas with us for your own use-case, reach out we would love to chat!